
香橙派AIpro是香橙派联合华为推出的开发板,功能非常强大,其部分参数表如下,

CPU里集成了AI处理器,非常适合做AI应用,但遗憾的是本人不是做这个方向的,后续等学习了相关AI知识后再来研究 :)
PS:比较奇怪的是CPU的具体型号没有提及,只写着4核64位处理器...
一 初始
收到CSDN邮寄的香橙派AIpro后打开,有以下几个东西,

- 电源适配器
- 电源线
- 32G TF卡,已经烧好华为的Linux系统 (基于Ubuntu22.04.3 LTS)
- 香橙派AIpro开发板
把TF卡插入开发板的卡槽,然后把电源适配器通过电源线接到板子的电源接口,接着把适配器插入插座,此时板子就会启动,风扇启动时会发出比较大的噪音,等启动好了之后就安静了。
然后通过HDMI线接到显示器上,显示如下,

PS:板子上有2个HDMI接口,只有靠近网口的那个是可以用的,另外一个用不了,原因未知。
此时可以看到系统登陆界面,默认用户是HwHiAiUser,密码是Mind@123,输入密码后登录系统,
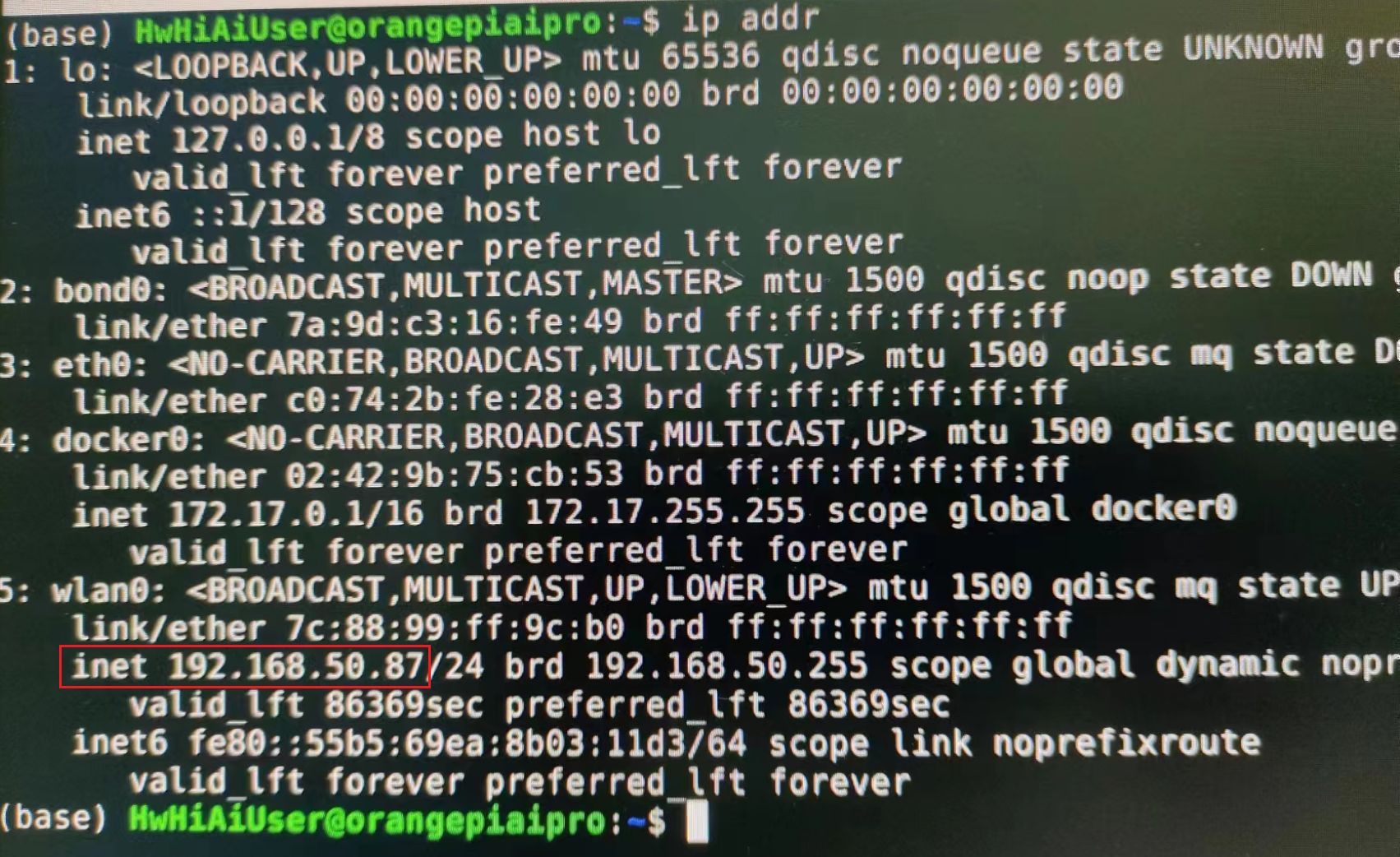
由于本人喜欢用SSH连接开发板,然后做开发,所以这里先把板子连上家里的WIFI,并获取其IP,如下红框,
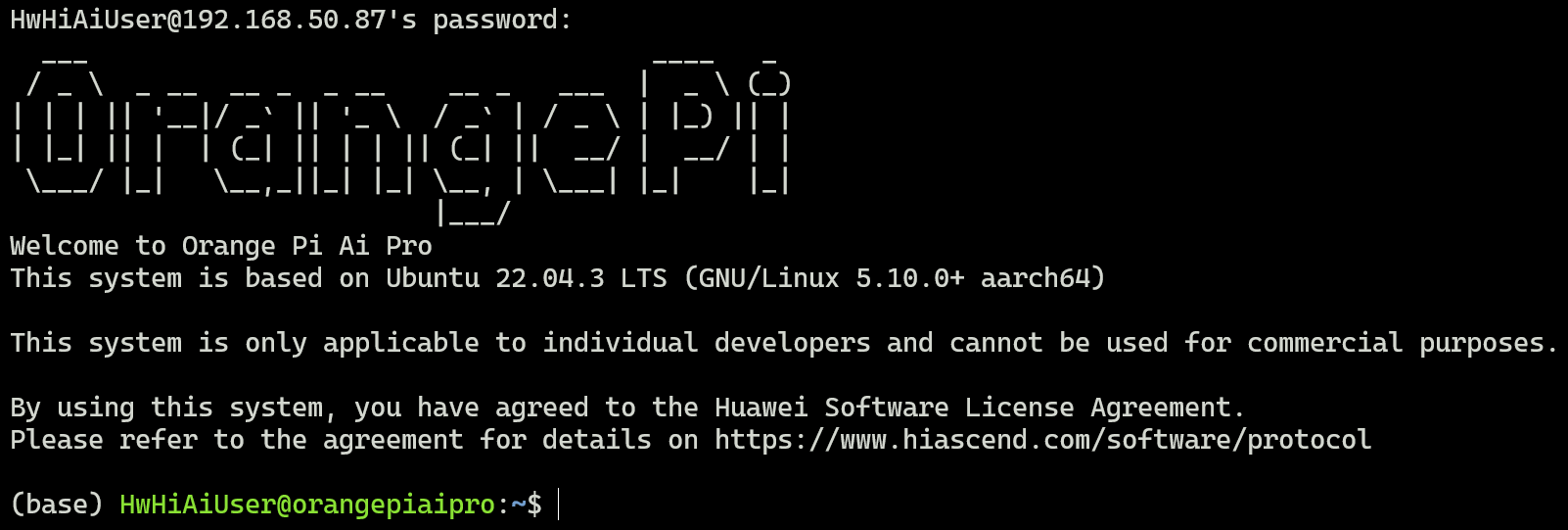
接着自己的电脑也连上这个WIFI,最后配置下SSH,这样电脑和开发板之间就可以通过SSH通信了,连接好后显示如下,
输入
df -h查看存储空间,

可以看到还有11G的存储空间供用户使用。
PS:这里要赞一下板子上安装的系统,基本所有必须的软件都安装好了,不用用户操心。
二 运行OPCUA服务器
首先尝试在香橙派AIpro上运行OPCUA服务器,并测试性能。
OPC UA(Open Platform Communications Unified Architecture)是一种先进的工业通信协议,设计用于实现设备与设备之间、设备与应用程序之间的安全、可靠、平台无关的数据交互。它是OPC基金会推出的新一代标准,旨在改进和替代早期的OPC规范,如OPC DA(Data Access)、OPC HDA(Historical Data Access)和OPC AE(Alarms and Events)等。
1. 搭建工程
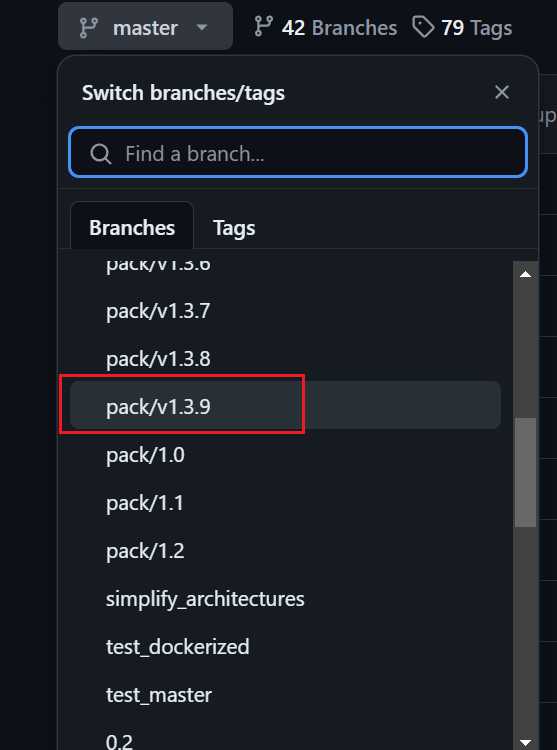
OPCUA使用开源库open62541,其地址是https://github.com/open62541/open62541,进入后选择1.3.9版本,然后进行下载,
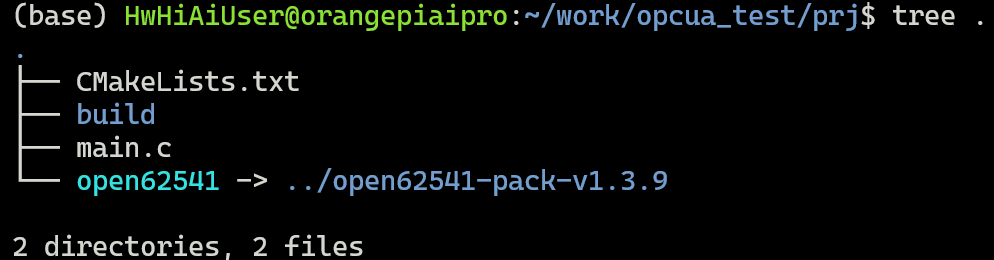
下载到Ubuntu里后解压,创建目录prj,并在这个目录里添加一个软链接指向open62541源码目录,同时创建CMakeLists.txt,build目录和main.c,最后工程结构如下,
CMakeLists.txt内容如下,
cmake_minimum_required(VERSION 3.5)
project(demo)
set(OPEN62541_VERSION "v1.3.9")
set(UA_NAMESPACE_ZERO "FULL" CACHE STRING "xxx" FORCE)
set(UA_ENABLE_AMALGAMATION ON CACHE BOOL "xxx" FORCE)
add_subdirectory(${CMAKE_CURRENT_SOURCE_DIR}/open62541)
include_directories(${CMAKE_CURRENT_SOURCE_DIR}/build/open62541)
add_executable(demo ${CMAKE_CURRENT_SOURCE_DIR}/main.c)
target_link_libraries(demo open62541)
这里开启了 Full Namespace0,这样会让open62541库变得很大,需要消耗的内存也很多,启动时会变慢,这样设置为了测试性能。
main.c内容如下,
#include "open62541.h"
#include <signal.h>
#include <stdlib.h>
#include <stdint.h>
UA_Boolean running = true;
static void stopHandler(int sign) {
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_SERVER, "received ctrl-c");
running = false;
}
bool addOneNode(uint32_t index, UA_Server *server)
{
UA_StatusCode ret = UA_STATUSCODE_GOOD;
UA_VariableAttributes attr = UA_VariableAttributes_default;
UA_UInt32 myInteger = index;
char name[16] = {0};
snprintf(name, 16, "Data%d", index);
UA_Variant_setScalarCopy(&attr.value, &myInteger, &UA_TYPES[UA_TYPES_UINT32]);
attr.description = UA_LOCALIZEDTEXT_ALLOC("en-US", name);
attr.displayName = UA_LOCALIZEDTEXT_ALLOC("en-US", name);
UA_NodeId myIntegerNodeId = UA_NODEID_STRING_ALLOC(1, name);
UA_QualifiedName myIntegerName = UA_QUALIFIEDNAME_ALLOC(1, name);
UA_NodeId parentNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER);
UA_NodeId parentReferenceNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_HASORDEREDCOMPONENT);
ret = UA_Server_addVariableNode(server, myIntegerNodeId, parentNodeId,
parentReferenceNodeId, myIntegerName,
UA_NODEID_NUMERIC(0, UA_NS0ID_BASEDATAVARIABLETYPE),
attr, NULL, NULL);
/* allocations on the heap need to be freed */
UA_VariableAttributes_clear(&attr);
UA_NodeId_clear(&myIntegerNodeId);
UA_QualifiedName_clear(&myIntegerName);
if (UA_StatusCode_isBad(ret))
{
return false;
}
else
{
return true;
}
}
int main()
{
signal(SIGINT, stopHandler);
signal(SIGTERM, stopHandler);
UA_Server *server = UA_Server_new();
UA_ServerConfig_setDefault(UA_Server_getConfig(server));
for (uint32_t i = 0; i < 25000; ++i)
{
if (addOneNode(i, server) == false)
{
printf("==> add node fail, index %d\n", i);
break;
}
}
UA_StatusCode retval = UA_Server_run(server, &running);
UA_Server_delete(server);
return retval == UA_STATUSCODE_GOOD ? EXIT_SUCCESS : EXIT_FAILURE;
}
这里在OPCUA服务器里创建25000个变量节点,这个数量很庞大,可以通过这个来简单测试下香橙派AIpro的性能。
2. 运行和测试
执行下面命令进行编译,
cd build
cmake ... && make -j4
在板子上编译Full Namespace0的open62541库会发现很慢,大概要20s才能编好,最后链接的时候也很慢。
生成的可执行文件demo有8M多,

然后运行,

实测发现程序启动很快,没有遇到卡顿,另外看到其默认所使用的端口号是4840,这样OPCUA服务器就启动好了。
接着是OPCUA客户端,本人电脑里安装了UaExpert,这是一个OPCUA客户端工具,可以用来连接OPCUA服务器。
打开后点击工具栏里的这个“+”号,
弹出窗口后点击Advanced,然后输入服务器的ip和端口号,
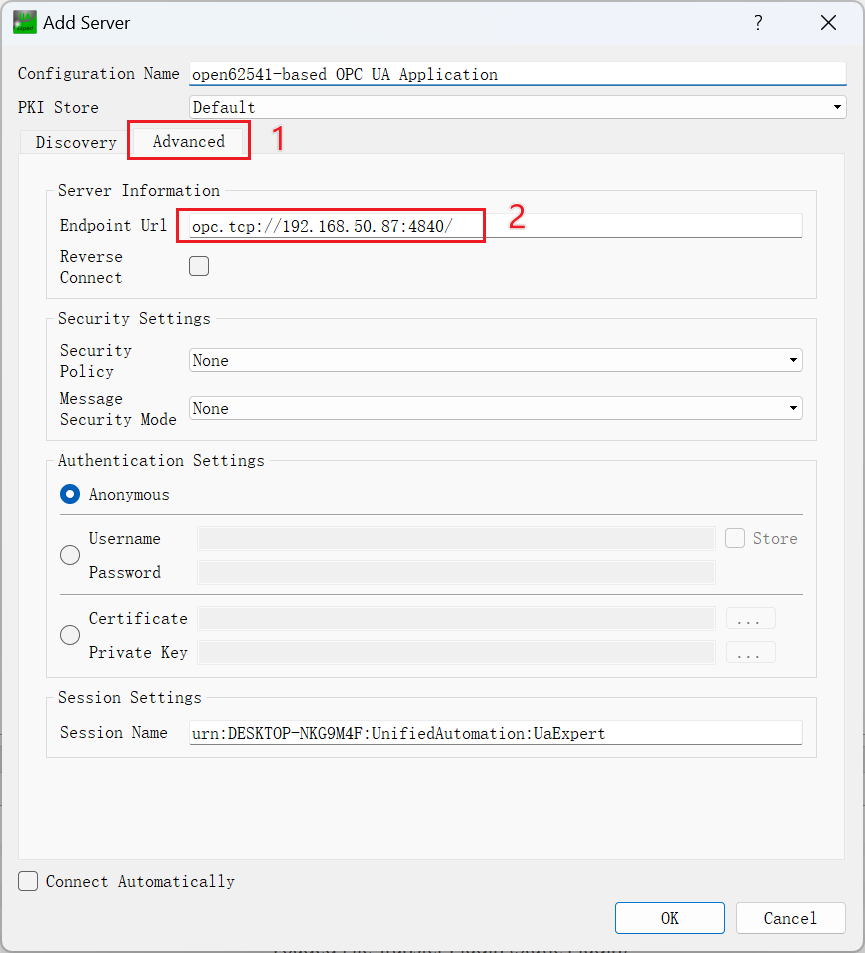
最后点击OK进行,得到如下显示,
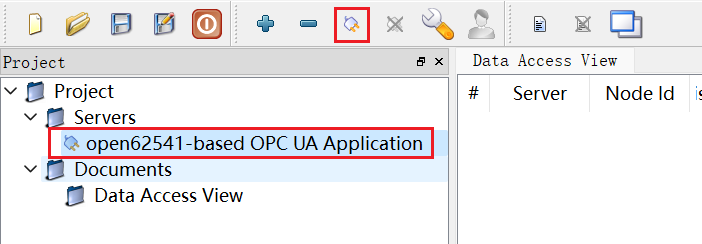
选中这个服务器,然后点击工具栏的连接按钮,连接成功后如下,
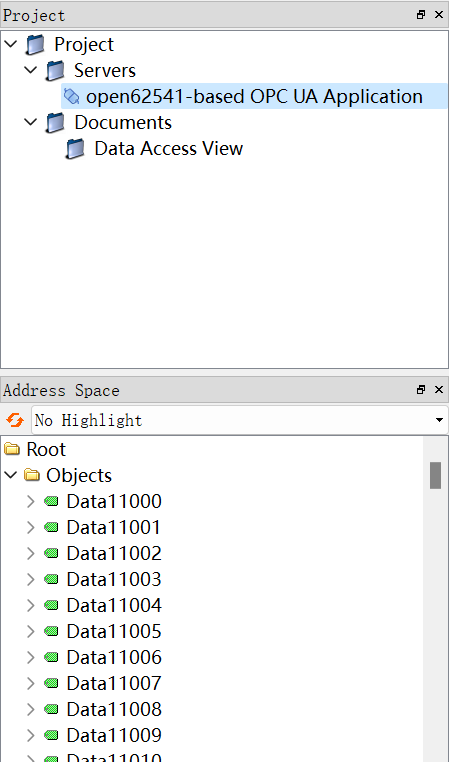
可以看到变量节点都在Objects目录下。
由于OPCUA服务器里有25000个变量节点,所以连接时会有卡顿,这里点击Objects目录,然后再点击其它节点,然后再点回Objects目录,这样可以让其不停的刷新,可以看出有明显的延迟,因为这需要不停的浏览服务器上的节点,如下log,

不过这是跟数据传输有关,因为节点很多,就需要传输大量数据,本来OPCUA就不是一个轻量级的协议。而在开发板上的服务器程序则运行很好,使用htop来查看服务器的消耗,可以看出很低,

三 运行DDS
DDS,全称Data Distribution Service(数据分发服务),是一个中间件协议和API标准,主要用于满足各种分布式实时通信应用需求,目前由对象管理组(OMG)发布和维护。
CycloneDDS是DDS的C++开源实现,是Eclipse下的 IoT项目,license是Eclipse Public License - v 2.0,可以免费使用,其Github地址是https://github.com/eclipse-cyclonedds/cyclonedds。
这一节展示如何在香橙派AIpro运行CycloneDDS
1. 搭建工程并编译
打开CyloneDDS网页,然后在右侧找到最新release的版本,
点进去后,下载源码的zip包,
下载好之后拷贝到开发板里并解压,然后进入源码目录去创建build目录,最后执行下面命令编译源码,
cd build
cmake -DCMAKE_INSTALL_PREFIX=/home/HwHiAiUser/work/dds_test/dds_install -DBUILD_EXAMPLES=ON. .
cmake --build .
编译完成后,如果想执行安装,那么就运行下面的命令,
cmake --build . --target install
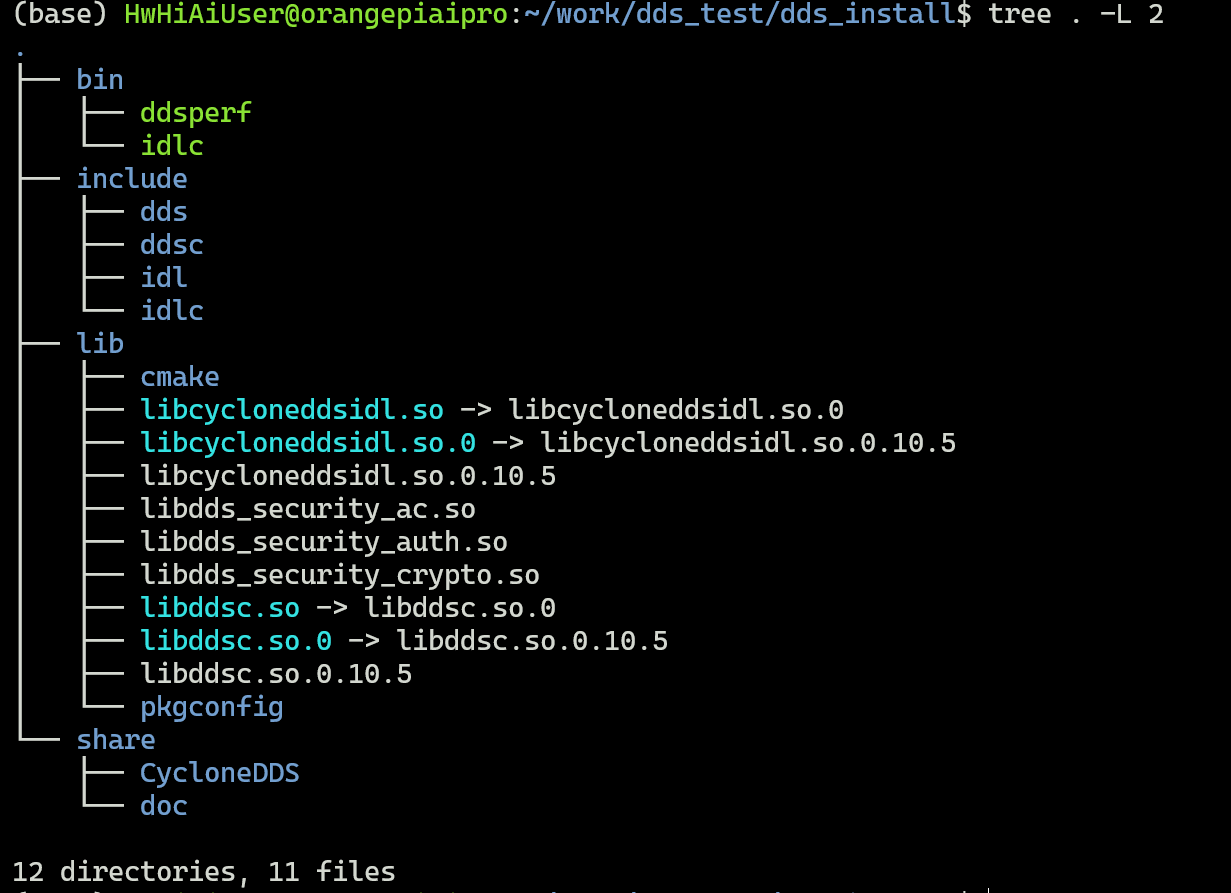
这样就可以把CyloneDDS的头文件,库以及例子都安装到指定的目录里了,这里是/home/HwHiAiUser/work/dds_test/dds_install
2. 运行例子
CycloneDDS的例子在编译时就已经编好了,

这里运行Roundtrip的例子,先运行RoundtripPong,然后再开一个终端运行RoundtripPing,最后得到以下显示,
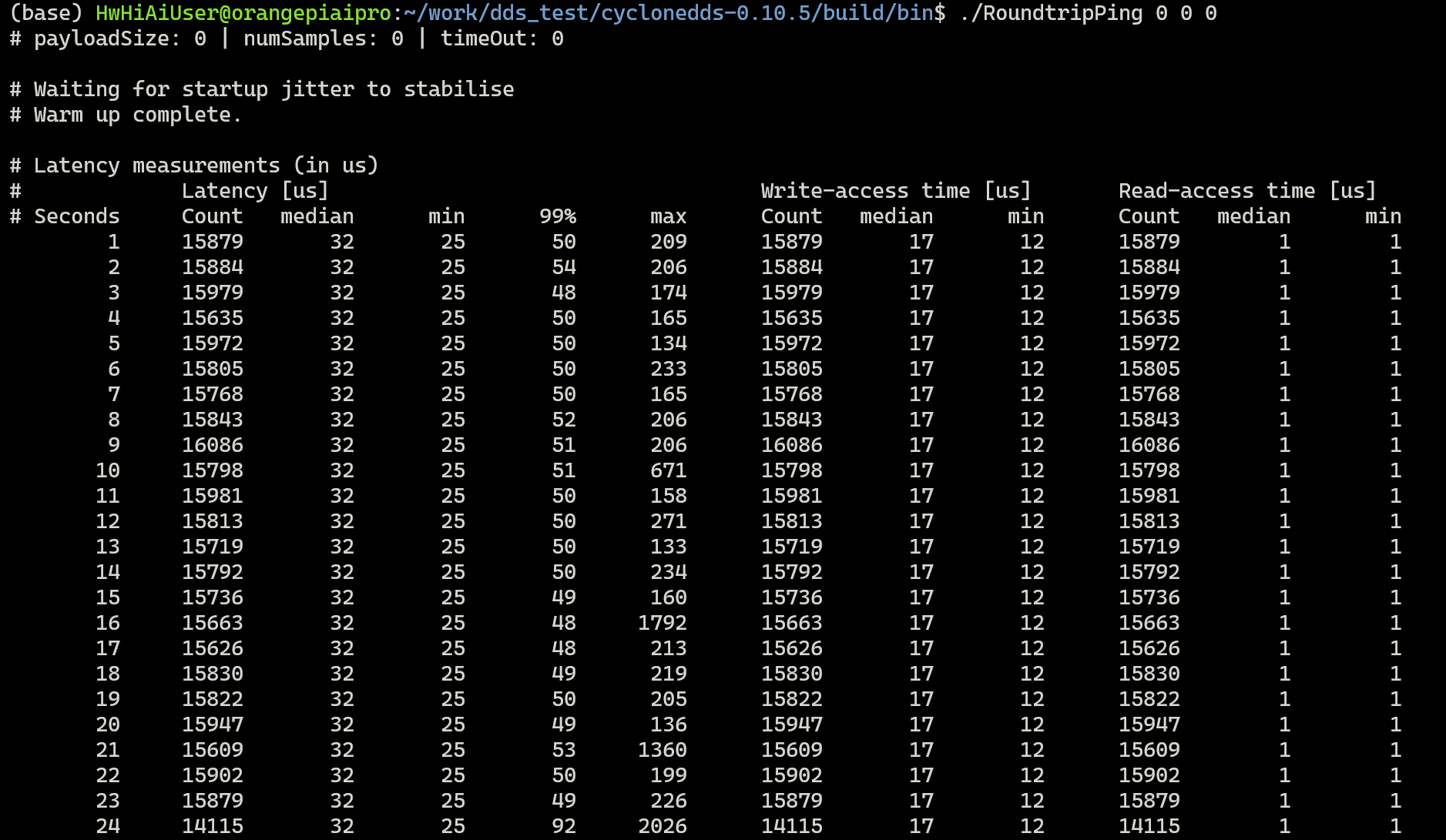
可以看出比较稳定,而且延时也很低。
四 总结
本文讲述了如何在香橙派AIpro上运行OPCUA服务器和DDS,可以看出香橙派AIpro运行OPCUA服务器和DDS毫无压力,整体性能很强,用于工业控制完全没有问题,就是系统可能要改成实时的,毕竟工控领域讲究稳定。
体验过程中发现有2个缺点:
- 散热不好,应该是芯片性能太强造成的,功耗高,即使开着系统什么也不做,也会发热厉害
- SSH连接有时会有迟钝,输入了命令要过几秒才会显示,应该也是和温度过高有关

昇腾万里,让智能无所不及
更多推荐





 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)