
OrangePi AIpro测评体验-Yolov5、OCR模型体验
非常荣幸受官方邀请体验OrangePi AIpro,本文介绍OrangePi AIpro测评Yolov5目标检测/OCR模型整个过程,并在OCR实例代码的基础上增加了摄像头检测的功能。总体来说OrangePi AIpro非常nice,非常适合部署一些小模型。
一、OrangePi AIpro介绍
作为业界首款基于昇腾深度研发的AI开发板,OrangePi AIpro无论在外观上、性能上还是技术服务支持上都非常优秀。采用昇腾AI技术路线,集成图形处理器,拥有8GB/16GB LPDDR4X,可以外接32GB/64GB/128GB/256GB eMMC模块,支持双4K高清输出,8/20 TOPS AI算力。
其丰富的接口更是赋予了OrangePi AIpro强大的可拓展性。包括两个HDMI输出、GPIO接口、Type-C电源接口、支持SATA/NVMe SSD 2280的M.2插槽、TF插槽、千兆网口、两个USB3.0、一个USB Type-C 3.0、一个Micro USB、两个MIPI摄像头、一个MIPI屏等,预留电池接口。
在操作系统方面,OrangePi AIpro支持Ubuntu、openEuler操作系统,满足大多数AI算法原型验证、推理应用开发的需求,可广泛适用于AI边缘计算、深度视觉学习及视频流AI分析、视频图像分析、自然语言处理、智能小车、机械臂、人工智能、无人机、云计算、AR/VR、智能安防、智能家居等领域,覆盖 AIoT各个行业。

在本次测评中OrangePi AIpro的配置为:8GB/16GB LPDDR4X,外接32GB eMMC模块,支持双4K高清输出,8 TOPS AI算力。
二、开机
经过数天的等待,终于到货啦~~,打开快递,实物如下图(包含一个电源线、电源插头以及OrangePi AIpro开发板):

因为是裸板,所以接上了鼠标、键盘、网线、显示器、电源,先通电看下效果,鼠标和键盘接了2个USB接口,显示器接HDMI0接口,插上网线和电源线:

开机的一瞬间,风扇呜呜呜的转了起来(一开始风扇转的很猛,有点吓人,进入系统就好了),我的显示器是27寸,成功亮了起来,进入系统(系统发来的时候是ubuntu22.04):
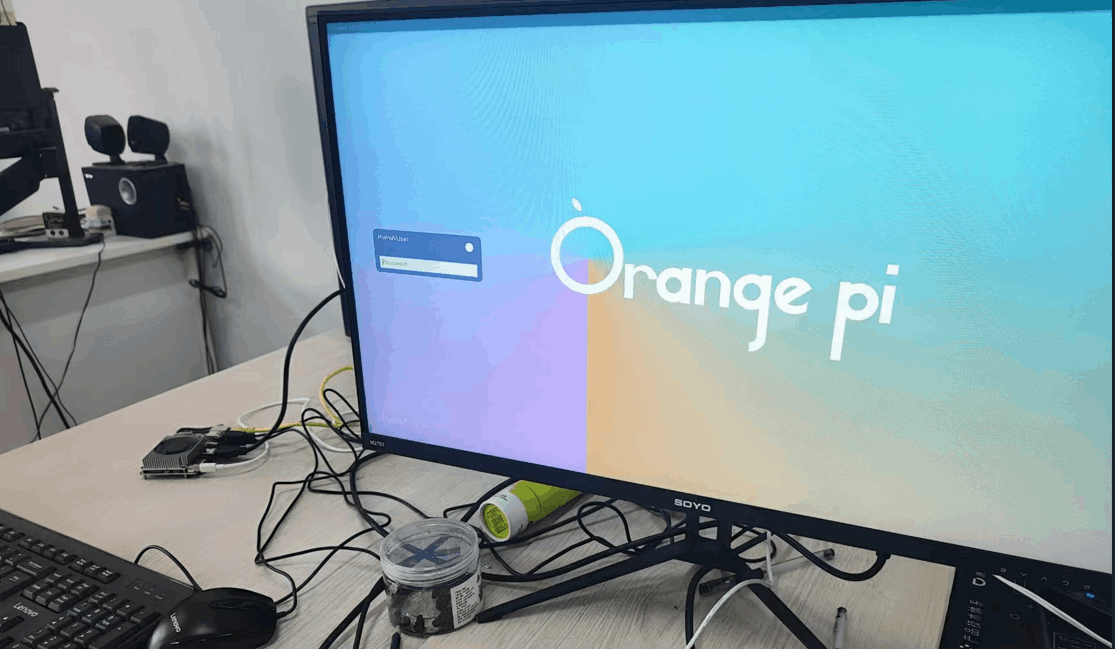
进入系统,打开终端,输入命令ip a,查看ip地址是192.168.1.177,然后记下ip地址,把显示器接回我的电脑,后续操作远程进行。
三、远程连接
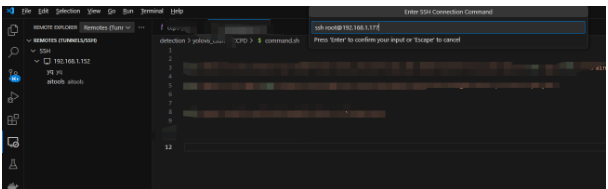
因为习惯用vscode开发,所以在自己电脑上用vscode远程连接OrangePi AIpro进行测试,使用vscode的ssh连接OrangePi AIpro:
输入密码连接成功:
连接成功之后,输入以下命令查看npu信息:
npu-smi info
如下图所示,显示了版本、内存等信息:

四、Yolov5模型体验
切换到HwHiAiUser用户,打开目录/home/HwHiAiUser/samples:
cd /home/HwHiAiUser/samples
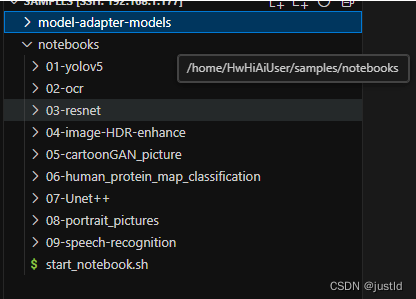
可以看到notebooks里面有很多示例,这是官方已经做好的,下面我们来体验一下。参考教程: https://metaxiaoyu.feishu.cn/docx/CE0bdHxyTocRGFxLoDPcG6I5nJd#tdsub
进入notebooks目录:
cd notebooks/
运行start_notebook.sh脚本:
bash start_notebook.sh
打开这个连接:
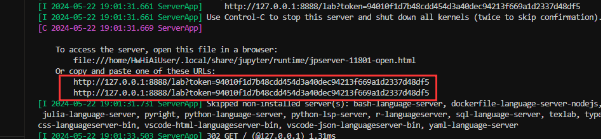
进来了,左边是官方的示例代码:
说在前面:OrangePi AIpro不支持onnx推理,所以要先把onnx模型转换为om模型,转换方法参考:https://www.hiascend.com/document/detail/zh/canncommercial/700/quickstart/quickstart/quickstart_18_0007.html
1、图片检测
进入相关目录,并打开jupyter文件:
依次运行代码块,注意,最后一个代码块修改了代码,因为我的OrangePi AIpro没有摄像头:
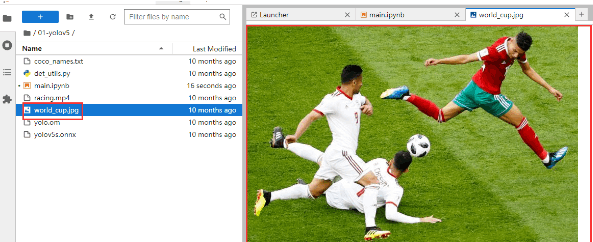
先看下要检测的图片长什么样:
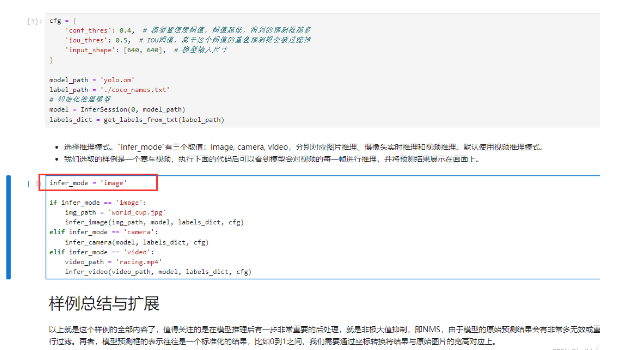
回去main.ipynb,运行推理代码块:
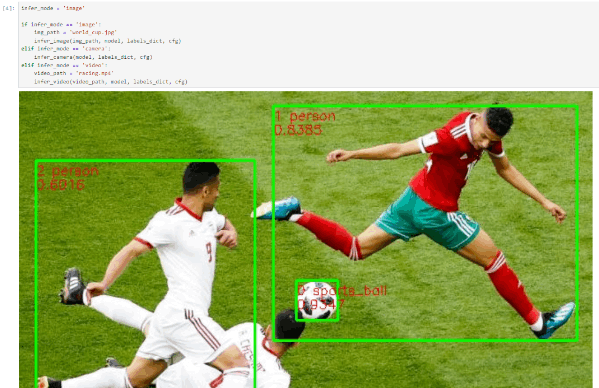
可以看到代码成功跑通了。
2、视频检测
可以看到代码里面还有个视频,改下代码,用视频试试:
在上面的代码块下面新开一个代码块,把以下内容加上去:
|
def infer_and_save_video(video_path, model, labels_dict, cfg, output_video='output.avi'): """视频推理""" image_widget = widgets.Image(format='jpeg', width=800, height=600) display(image_widget)
# 读入视频 cap = cv2.VideoCapture(video_path) fourcc = cv2.VideoWriter_fourcc(*'XVID') width = int(cap.get(3)) height = int(cap.get(4)) fps = cap.get(cv2.CAP_PROP_FPS) export_cap = cv2.VideoWriter(output_video, fourcc, fps, (width, height), True) while True: ret, img_frame = cap.read() if not ret: break # 对视频帧进行推理 image_pred = infer_frame_with_vis(img_frame, model, labels_dict, cfg, bgr2rgb=True) export_cap.write(image_pred) # 写入视频 image_widget.value = img2bytes(image_pred) export_cap.release()
video_path = 'racing.mp4' infer_and_save_video(video_path, model, labels_dict, cfg) |
如下图:

运行新加入的代码块,即可在推理结束后得到output.avi:
视频如下:
https://www.bilibili.com/video/BV1Yi421D7ew/?spm_id_from=333.1350.jump_directly
3、摄像头检测
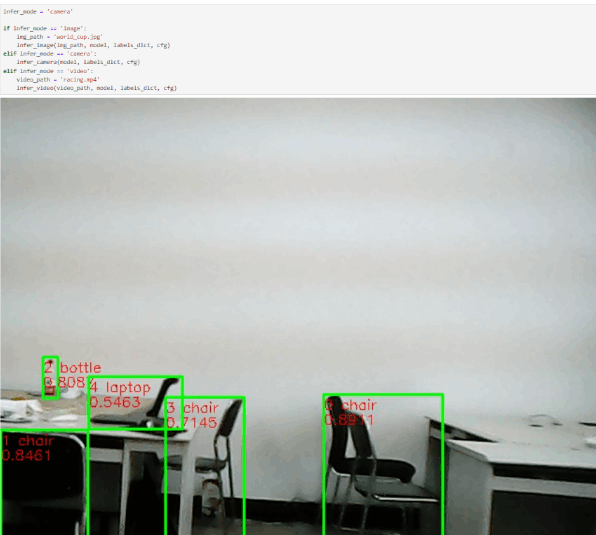
体验了图片和视频检测,那肯定不能缺了摄像头检测,把不知道不知道多久前买的摄像头安排上:

把代码模式改成摄像头模式,并运行代码,成功运行,而且效果非常好,达到了实时:
五、OCR模型体验
说在前面:OrangePi AIpro不支持onnx推理,所以要先把onnx模型转换为om模型,转换方法参考:https://www.hiascend.com/document/detail/zh/canncommercial/700/quickstart/quickstart/quickstart_18_0007.html
接下来进入ocr目录,测试一下ocr的效果:

一直运行代码,就可以跑出如下的效果,但是示例只给出了检测图片,把他扩展到摄像头检测:
OCR摄像头检测的代码在下面:
|
if not os.path.exists('infer_result'): os.makedirs('infer_result') ans = {} import ipywidgets as widgets import numpy as np def img2bytes(image): """将图片转换为字节码""" return bytes(cv2.imencode('.jpg', image)[1])
def find_camera_index(): max_index_to_check = 10 # Maximum index to check for camera
for index in range(max_index_to_check): cap = cv2.VideoCapture(index) if cap.read()[0]: cap.release() return index
# If no camera is found raise ValueError("No camera found.")
# 获取摄像头 camera_index = find_camera_index() cap = cv2.VideoCapture(camera_index) # 初始化可视化对象 image_widget = widgets.Image(format='jpeg', width=1280, height=720) display(image_widget) while True: # 对摄像头每一帧进行推理和可视化 _, img_src = cap.read() # image_pred = infer_frame_with_vis(img_frame, model, labels_dict, cfg) # basename = os.path.basename(IMAGE_PATH)
image_h, image_w = img_src.shape[:2]
det_input_tensor = det_model.preprocess(img_src)
output = det_model.infer(det_input_tensor)
bboxes = det_model.postprocess(output) # im = Image.open(IMAGE_PATH) im = Image.fromarray(img_src) draw = ImageDraw.Draw(im) ans['image_name'] = basename ans['result'] = [] for bbox in bboxes: bbox_detail = {} x1 = int(bbox[0] / det_model.model_width * image_w) y1 = int(bbox[1] / det_model.model_height * image_h) x2 = int(bbox[2] / det_model.model_width * image_w) y2 = int(bbox[3] / det_model.model_height * image_h) draw.line([(x1, y1), (x1, y2), (x2, y2), (x2, y1), (x1, y1)], fill='red', width=2) bbox_detail['bbox'] = [x1, y1, x1, y2, x2, y2, x2, y1] res = ','.join(map(str,bbox_detail['bbox'])) print(f'det result: {res}') crop_img = img_src[y1:y2, x1:x2]
rec_input_tensor = rec_model.preprocess(crop_img) rec_output = rec_model.infer(rec_input_tensor) bbox_detail['text'] = rec_model.postprocess(rec_output) print(f'rec result: {bbox_detail["text"]}') ans['result'].append(bbox_detail)
image_widget.value = img2bytes(np.array(im)) cap.release() |
把代码放到jupyter文件中运行(因为有些摄像头比较古老,而且这本书有点反光,图片质量不行),下面是运行截图,准确率还是挺不错的,但是非常卡顿:

图片分辨率是576x960,识别结果如下图:
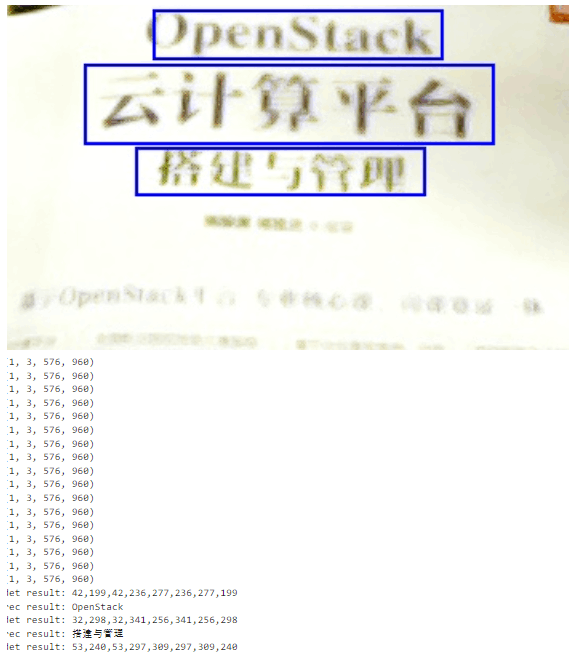
OCR识别需要先检测图片中所有文本块的位置,然后分别裁剪下来送入识别模型进行识别,每个图片需要处理的时间比较长,OrangePi AIpro的算力有点捉襟见肘。
六、总结
1、从官方提供的示例代码中的检测结果来看,视频非常流畅,从onnx模型可以看到YOLOV5目标检测图片分辨率是640x640,这个分辨率下能有这个表现,很惊艳;
2、可能以前都没怎么接触过边缘部署的原因,总是主观认为没有GPU很难在工业场景下达到实时检测的同时保持好的检测效果,但是OrangePi AIpro给我的感觉是可以,个人觉得OrangePi AIpro会在工业场景下有非常亮眼的表现;
3、对于示例代码中的OCR模型来说算力有点捉襟见肘,后续如果时间充足会考虑部署一些小的OCR模型进行测试。

昇腾万里,让智能无所不及
更多推荐




 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)