
【OrangePi AIpro】从开箱到第一个AI应用开发
感谢CSDN官方邀请,本文开箱并测试 OrangePi AIpro开发板的功能,同时体验了0-1从烧录到搭建第一个AI应用的过程并做相应记录。
第一章 OrangePi AIpro介绍和开发环境搭建
1.1 OrangePi AIpro介绍
OrangePi AIpro(8T)采用昇腾AI技术路线,具体为4核64位处理器+AI处理器,集成图形处理器,支持8TOPS AI算力,拥有8GB/16GB LPDDR4X,可以外接32GB/64GB/128GB/256GB eMMC模块,支持双4K高清输出。Orange Pi AIpro支持Ubuntu、openEuler操作系统,满足大多数AI算法原型验证、推理应用开发的需求。
这块板子的特色在于香橙派 X 华为昇腾,可以接入华为昇腾的生态,基于Ascend的CANN架构、AI框架、开发工具链等进行相关应用开发。(总结:作为业界首款基于昇腾深度研发的AI开发板,OrangePi AIpro无论在外观上、性能上还是技术服务支持上都非常优秀)。


1.2 在虚拟机上配置CANN
1、在VMware Workstation 16安装Ubuntu 22.04系统
① 在Ubuntu官网下载下载Ubuntu 22.04.4 LTS。

② 打开安装VMware Workstation 16 Player安装的VMware软件,选择“创建新虚拟机”。
③ 选择①中下载的镜像文件,单击“下一步”。选择虚拟机安装位置。

指定Ubuntu可以使用的内存和处理器核数,修改为16G内存与8核处理器。
指定磁盘容量,至少分配50GB,选择“将虚拟磁盘拆分成多个文件”,单击“下一步”。
④ 其他默认即可,配置完成后单击“下一步”即可进入虚拟机开始系统安装。
⑤ 完成Ubuntu 22.04系统安装
2、在正式安装CANN前先进行相关依赖
① 更换下载源(使用阿里云)
执行如下命令检查源是否可用。如果命令执行报错或者后续安装依赖时等待时间过长甚至报错,则检查网络是否连接或者把“/etc/apt/sources.list”文件中的源更换为可用的源或使用镜像源。
sudo apt-get update
# pip永久换源
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config set global.trusted-host mirrors.aliyun.com
tips:也可以用华为镜像,具体参考官网。
② 检查用户的umask
lhh@virtual:~$ umask
0022
如果umask不等于0022,在.bashrc文件的最后一行添加umask 0022后保存
sudo nano ~/.bashrc
// ctrl+o保存,ctrl+x退出编辑器
source ~/.bashrc
② 安装依赖
sudo apt-get install -y gcc g++ make cmake zlib1g zlib1g-dev openssl \\
libsqlite3-dev libssl-dev libffi-dev libbz2-dev libxslt1-dev unzip \\
pciutils net-tools libblas-dev gfortran libblas3
安装pip3
sudo apt-get install python3-pip
③ 安装python开发相关依赖包
pip3 install attrs
pip3 install numpy
pip3 install decorator
pip3 install sympy
pip3 install cffi
pip3 install pyyaml
pip3 install pathlib2
pip3 install psutil
pip3 install protobuf
pip3 install scipy
pip3 install requests
pip3 install absl-py
至此,完成依赖包的安装,接下来就是CANN的正式编译安装了。
官方tips:依赖安装完成后,请用户恢复为原umask值(删除.bashrc文件中umask 0022一行)。基于安全考虑,建议用户将umask值改为0027。
3、编译安装CANN
① 下载CANN包 在官网查看并下载CANN软件“Ascend-cann-toolkit_{version}_linux-x86_64.run” (快速链接)
② 在终端中进入安装包所在目录,增加软件包的可执行权限后进行安装
chmod +x Ascend-cann-toolkit_6.2.RC2_linux-x86_64.run
./Ascend-cann-toolkit_6.2.RC2_linux-x86_64.run --install
安装完成后,若显示如下信息,则说明软件安装成功:
[INFO] xxx install success
③ 在~/.bashrc中配置开发套件包的环境变量,方便随地可调用CANN相关指令(如atc)。
sudo nano ~/.bashrc
在~/.bashrc最后添加以下。注意与安装路径匹配。
. /home/lhh/Ascend/ascend-toolkit/set_env.sh
export LD_LIBRARY_PATH=/home/lhh/Ascend/ascend-toolkit/latest/x86_64-linux/devlib/:$LD_LIBRARY_PATH
export DDK_PATH=/home/lhh/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub
使环境配置生效,这样就不需要反复去配置环境了。
source nano ~/.bashrc
3、测试模型转换工具ATC 昇腾张量编译器(Ascend Tensor Compiler,简称ATC)是异构计算架构CANN体系下的模型转换工具, 它可以将开源框架的网络模型(如Caffe、TensorFlow、ONNX、MindSpore)以及Ascend IR定义的单算子描述文件(json格式)转换为昇腾AI处理器支持的.om格式离线模型。
ATC的工作流程大致如下: stage1:网络模型经过Parser解析后,转换为中间态IR Graph。 stage2:中间态IR经过图准备、图拆分、图优化、图编译等一系列操作后,转成适配昇腾AI处理器的离线模型.om模型。 stage3:转换后的离线模型上传到板端环境,通过AscendCL接口加载模型文件实现推理过程。
至于为什么要大费周章在虚拟机上安装CANN环境,反正板子有环境直接在板子上做模型转换不就行了吗,[狗头]因为板子性能终归不及PC端,实测板端模型转换十分耗时,在Linux虚拟机上进行模型转换视模型大小也需要一到几分钟不等的时间。
以下以ONNX模型转为om模型为例测试ATC工具是否正常工作。 ① 以我以mobilenet_v2图像分类的预训练模型.onnx文件为例,进入模型文件所在位置。通过onnx可视化可以看到模型的输入为1x1x224x224,且输入input_name即为input。
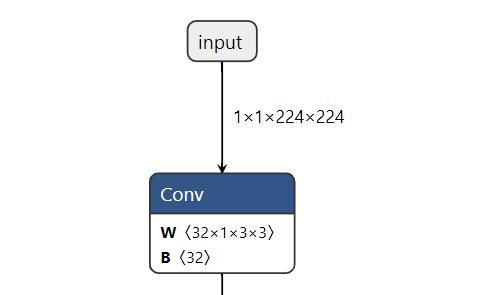
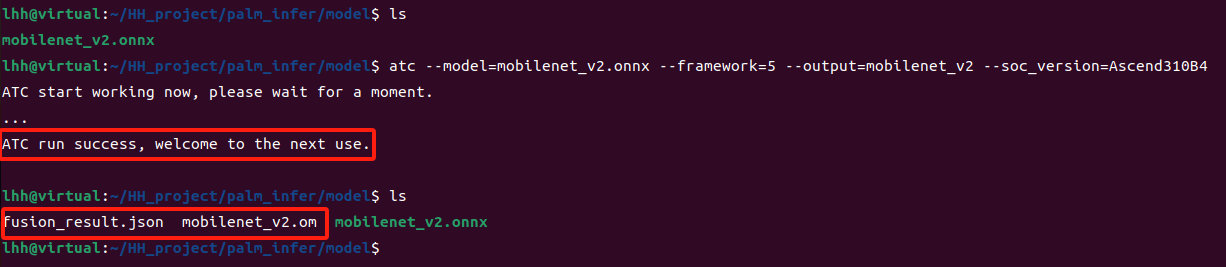
② 执行如下命令生成离线模型,atc有众多参数可选择,但是有必须使用的参数介绍如下表所示。ATC说明文档
atc --model=mobilenet_v2.onnx --framework=5 --output=mobilenet_v2 --soc_version=Ascend310B4
|
参数 |
说明 |
|
model |
原始模型文件,填写模型文件时需要带上格式,如.onnx |
|
weight |
原始模型权重,该参数在转换Caffe模型场景下使用。 |
|
framework |
0:Caffe; 1:MindSpore; 3:Tensorflow; 5:ONNX |
|
output |
保存转换后的om离线推理模型文件路径。 |
|
soc_version |
处理器型号,填写“Ascend310B4”。 |
③ 输出以下info则模型转换成功,得到mobilenet_v2.om文件以及fusion_result.json文件。
ATC start working now, please wait for a moment.
...
ATC run success, welcome to the next use.
第二章 开箱和板端环境搭建
拿到手时首先OrangePi AIpro这个板子是比之前用过的树莓派、香橙派要稍大一些的,还配备了TypeC接口的20V PD-65W适配器和散热器。官方已经贴心地提前烧录好了opiaipro ubuntu22.04系统(内部已装好CANN,如果没有预装系统的话,可以查看官方镜像源)。如果自行编译安装,这里面需要注意的是虚拟机上的CANN安装包是不可以直接拿来用的,需要下载安装Ascend-cann-toolkit_7.0.0_linux-aarch64.run,具体的话可以通过官方百度云盘或者昇腾官方资源下载。

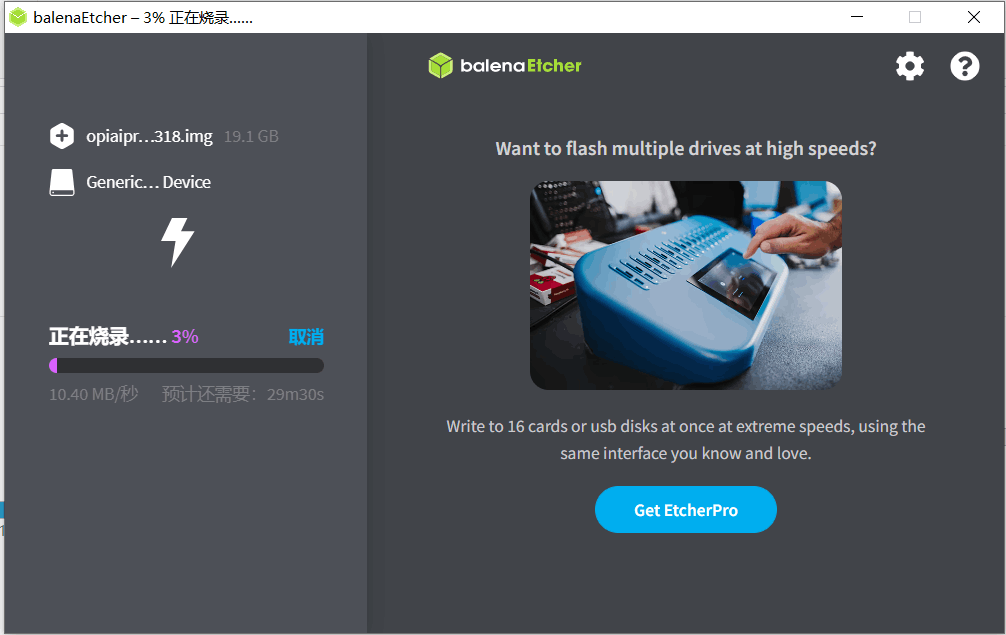
2.1 板端ubuntu系统烧录
根据官方给的Linux镜像烧录工具-balenEther进行系统镜像烧录,镜像也为官方提供的opiaipro_ubuntu22.04_desktop_aarch64_20240318.img。

2.2 板端编译安装CANN框架--
① 下载CANN包 查看并下载CANN软件“Ascend-cann-toolkit_{version}_linux-aarch64.run” (香橙派资源快速链接、昇腾官方资源)
② 在终端中进入安装包所在目录,增加软件包的可执行权限后进行安装
chmod +x Ascend-cann-toolkit_7.0.0_linux-aarch64.run
sudo ./Ascend-cann-toolkit_7.0.0_linux-aarch64.run --install
安装完成后,若显示如下信息,则说明软件安装成功:
Toolkit: Ascend-cann-toolkit_7.0.0_linux-aarch64 install success, installed in /home/HwHiAiUser/Ascend.
③ 在~/.bashrc中配置开发套件包的环境变量,方便随地可调用CANN相关指令(如atc)。
sudo nano ~/.bashrc
在~/.bashrc最后添加以下。注意与安装路径匹配。
. /home/HwHiAiUser/Ascend/ascend-toolkit/set_env.sh
export LD_LIBRARY_PATH=/home/HwHiAiUser/Ascend/ascend-toolkit/latest/aarch64-linux/devlib/:$LD_LIBRARY_PATH
export DDK_PATH=/home/HwHiAiUser/Ascend/ascend-toolkit/latest/
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub
使环境配置生效,这样就不需要反复去配置环境了。
source ~/.bashrc
2.3 测试Ubuntu系统和CANN是否正常运行
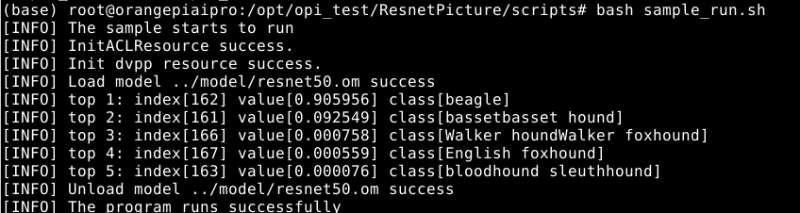
在终端窗口,执行cd /opt/opi_test/ResnetPicture命令,进入样例目录,运行预训练的ResnetPicture推理进行图像分类,该样例是基于PyTorch框架的ResNet50模型,对jpg图片分类,并在终端显示该图片的Top5置信度的分类ID、分类名称。
su root
cd /opt/opi_test/ResnetPicture/scripts
bash sample_run.sh

第三章 编译构建第一个推理样例:图片分类
前面我们已经通过系统自带的demo测试了CANN的可用性,那么如何去搭建这么一个图像分类推理框架呢。
3.1 在虚拟机转换得到.om模型
获取PyTorch框架的ResNet50模型(resnet50.onnx ),并转换为昇腾AI处理器能识别的模型(resnet50.om)。可以用npu-smi info查看板子的信息,即soc版本,OrangePi AIpro是Ascend310B4。

wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/resnet50/resnet50.onnx
atc --model=resnet50.onnx --framework=5 --output=resnet50 --input_shape="actual_input_1:1,3,224,224" --soc_version=Ascend310B4
3.2 CLion远程开发
我一般采用CLion+SSH远程连接板子,采用远程文件映射和编译进行应用开发,CLion的配置和使用可以参考我之前的一篇博客(CLion+Opencv+QT开发相关)中的CLion安装配置章节。
1、新建工程
首先是在CMakeLists.txt上链接相关库,如我这里会用到Ascend和Opencv,因此分别配置如下:
配置Ascend,root安装默认以下路径/usr/local/Ascend/ascend-toolkit,如果你是非root安装的话就需要自行根据安装的位置进行修改。
// 配置Ascend,root安装默认以下路径
set(INC_PATH $ENV{DDK_PATH})
if (NOT DEFINED ENV{DDK_PATH})
set(INC_PATH "/usr/local/Ascend/ascend-toolkit/latest")
message(STATUS "set default INC_PATH: ${INC_PATH}")
else()
message(STATUS "set INC_PATH: ${INC_PATH}")
endif ()
set(LIB_PATH $ENV{NPU_HOST_LIB})
if (NOT DEFINED ENV{NPU_HOST_LIB})
set(LIB_PATH "/usr/local/Ascend/ascend-toolkit/latest/runtime/lib64/stub")
message(STATUS "set default LIB_PATH: ${LIB_PATH}")
else()
message(STATUS "set LIB_PATH: ${LIB_PATH}")
endif ()
include_directories(
${INC_PATH}/runtime/include/
)
link_directories(
${LIB_PATH}
)
链接Opencv,板子上的opencv版本是4.5.4,可以通过pkg-config --modversion opencv4命令来查看opencv4版本,如果你是装的opencv2/3的话,用pkg-config opencv --modversion查看版本信息。
# OpenCV
find_package(OpenCV 4.5.4 REQUIRED)
find_package(OpenCV COMPONENTS core highgui imgproc imgcodecs)
链接工程需要的所有包
target_link_libraries(testinf // project_name
ascendcl
acl_dvpp
acllite_dvpp_lite
acllite_om_execute
acllite_common
stdc++
dl
rt
${OpenCV_LIBS}
)
2、编辑main.cpp,实现图片读取、NPU资源初始化、模型加载和推理、资源释放等功能。
-
构造ResnetCls类实现初始化资源、图片数据预处理、模型推理、推理后处理、释放资源等功能。
class ResnetCls {
public:
ResnetCls (int32_t device, const char* ModelPath, int32_t modelWidth, int32_t modelHeight);
~ResnetCls();
Result InitResource(); // 初始化资源
Result ProcessInput(const string testImgPath); // 处理输入图片
Result Inference(); // 模型推理
Result GetResult(); // 得到推理结果
private:
void ReleaseResource(); // 释放资源
int32_t deviceId_; // 设备编号
aclrtContext context_; // context
aclrtStream stream_; // stream
uint32_t modelId_; // 模型编号
const char* modelPath_; // 模型路径
int32_t modelWidth_; // 输入模型图片width
int32_t modelHeight_; // 输入模型图片height
aclmdlDesc *modelDesc_; // 表示模型描述信息
aclmdlDataset *inputDataset_; // 描述模型推理时的输入数据、输出数据
aclmdlDataset *outputDataset_;
aclrtRunMode runMode_; // 0:运行在Device的Control CPU或板端环境上。
void* inputBuffer_;
void *outputBuffer_;
size_t inputBufferSize_;
float* imageBytes;
String imagePath;
Mat srcImage;
};
ResnetCls::ResnetCls(int32_t device, const char* modelPath,
int32_t modelWidth, int32_t modelHeight) :
deviceId_(device), context_(nullptr), stream_(nullptr), modelId_(0),
modelPath_(modelPath), modelWidth_(modelWidth), modelHeight_(modelHeight),
modelDesc_(nullptr), inputDataset_(nullptr), outputDataset_(nullptr)
{
}
ResnetCls::~ResnetCls()
{
ReleaseResource();
}
-
初始化资源,需要依次申请如下运行管理资源:Device、Context、Stream,使用AscendCL接口开发应用时,必须先调用aclInit接口,否则可能会导致后续系统内部资源初始化出错,进而导致其它业务异常。函数原型为:
aclError aclInit(const char *configPath) // 可将配置文件配置为空json串(即配置文件中只有{})
// 依次申请如下运行管理资源:Device、Context、Stream
const char *aclConfigPath = ""; // 可将配置文件配置为空json串
aclError ret = aclInit(aclConfigPath);
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclInit failed, errorCode is %d", ret);
return FAILED;
}
ret = aclrtSetDevice(deviceId_); // 指定当前线程中用于运算的Device
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclrtSetDevice failed, errorCode is %d", ret);
return FAILED;
}
ret = aclrtCreateContext(&context_, deviceId_); // 当前进程或线程中显式创建一个Context
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclrtCreateContext failed, errorCode is %d", ret);
return FAILED;
}
ret = aclrtCreateStream(&stream_); // 创建一个Stream
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclrtCreateStream failed, errorCode is %d", ret);
return FAILED;
}
加载模型并生成模型信息,即加载前面转好的resnet50.om,因为我在转换的时候没用到Ascend中的DVPP和AIPP模块(图片处理模块,如果在转换的时候加入config文件后续可以调用DVPP、AIPP进行输入图片预处理,不过没有的话用opencv处理也是一样的)。
// load model from file
ret = aclmdlLoadFromFile(modelPath_, &modelId_);
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclmdlLoadFromFile failed, errorCode is %d", ret);
return FAILED;
}
// create description of model
modelDesc_ = aclmdlCreateDesc();
ret = aclmdlGetDesc(modelDesc_, modelId_);
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclmdlGetDesc failed, errorCode is %d", ret);
return FAILED;
}
ret = aclrtGetRunMode(&runMode_);
if (ret == FAILED) {
ERROR_LOG("get runMode failed, errorCode is %d", ret);
return FAILED;
}
描述输入输出,每个输入/输出的内存地址、内存大小用aclDataBuffer类型的数据来描述。
// create data set of input
inputDataset_ = aclmdlCreateDataset();
size_t inputIndex = 0;
inputBufferSize_ = aclmdlGetInputSizeByIndex(modelDesc_, inputIndex);
aclrtMalloc(&inputBuffer_, inputBufferSize_, ACL_MEM_MALLOC_HUGE_FIRST);
aclDataBuffer *inputData = aclCreateDataBuffer(inputBuffer_, inputBufferSize_);
ret = aclmdlAddDatasetBuffer(inputDataset_, inputData);
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclmdlAddDatasetBuffer failed, errorCode is %d", ret);
return FAILED;
}
// create data set of output
outputDataset_ = aclmdlCreateDataset();
size_t outputIndex = 0;
size_t modelOutputSize = aclmdlGetOutputSizeByIndex(modelDesc_, outputIndex);
aclrtMalloc(&outputBuffer_, modelOutputSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclDataBuffer *outputData = aclCreateDataBuffer(outputBuffer_, modelOutputSize);
ret = aclmdlAddDatasetBuffer(outputDataset_, outputData);
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclmdlAddDatasetBuffer failed, errorCode is %d", ret);
return FAILED;
}
-
处理输入图片,对输入图片进行标准化和resize等操作,计算处理后的图片byte并分配内存。
namespace {
const float min_chn_0 = 123.675;
const float min_chn_1 = 116.28;
const float min_chn_2 = 103.53;
const float var_reci_chn_0 = 0.0171247538316637;
const float var_reci_chn_1 = 0.0175070028011204;
const float var_reci_chn_2 = 0.0174291938997821;
}
Result ResnetCls::ProcessInput(const string testImgPath)
{
// read image from file by cv
imagePath = testImgPath;
srcImage = imread(testImgPath);
Mat resizedImage;
// zoom image to modelWidth_ * modelHeight_
resize(srcImage, resizedImage, Size(modelWidth_, modelHeight_));
// get properties of image
int32_t channel = resizedImage.channels();
int32_t resizeHeight = resizedImage.rows;
int32_t resizeWeight = resizedImage.cols;
// data standardization
float meanRgb[3] = {min_chn_2, min_chn_1, min_chn_0};
float stdRgb[3] = {var_reci_chn_2, var_reci_chn_1, var_reci_chn_0};
// create malloc of image, which is shape with NCHW
imageBytes = (float*)malloc(channel * resizeHeight * resizeWeight * sizeof(float));
memset(imageBytes, 0, channel * resizeHeight * resizeWeight * sizeof(float));
// 做BGR->RGB通道转换
uint8_t bgrToRgb=2;
// image to bytes with shape HWC to CHW, and switch channel BGR to RGB
for (int c = 0; c < channel; ++c)
{
for (int h = 0; h < resizeHeight; ++h)
{
for (int w = 0; w < resizeWeight; ++w)
{
int dstIdx = (bgrToRgb - c) * resizeHeight * resizeWeight + h * resizeWeight + w;
imageBytes[dstIdx] = static_cast<float>((resizedImage.at<cv::Vec3b>(h, w)[c] -
1.0f*meanRgb[c]) * 1.0f*stdRgb[c] );
}
}
}
return SUCCESS;
}
-
将输入数据memcpy到npu,并进行模型推理
aclError ret = aclrtMemcpy(inputBuffer_, inputBufferSize_, imageBytes, inputBufferSize_, kind);
if (ret != ACL_SUCCESS) {
ERROR_LOG("memcpy failed, errorCode is %d", ret);
return FAILED;
}
// inference
ret = aclmdlExecute(modelId_, inputDataset_, outputDataset_); // 执行模型推理,直到返回推理结果
if (ret != ACL_SUCCESS) {
ERROR_LOG("execute model failed, errorCode is %d", ret);
return FAILED;
}
-
后处理,根据output(各个类的概率)找到概率最大的类,通过label.h对应找到分类结果。
-
释放资源,与前面申请Device、Context、Stream的顺序相反,依次释放inputBuffer_、outputBuffer_、modelDesc_、Stream、Context、Device。
void ResnetCls::ReleaseResource()
{
aclError ret;
// release resource includes acl resource, data set and unload model
aclrtFree(inputBuffer_);
inputBuffer_ = nullptr;
(void)aclmdlDestroyDataset(inputDataset_);
inputDataset_ = nullptr;
aclrtFree(outputBuffer_);
outputBuffer_ = nullptr;
(void)aclmdlDestroyDataset(outputDataset_);
outputDataset_ = nullptr;
ret = aclmdlDestroyDesc(modelDesc_);
if (ret != ACL_SUCCESS) {
ERROR_LOG("destroy description failed, errorCode is %d", ret);
}
ret = aclmdlUnload(modelId_);
if (ret != ACL_SUCCESS) {
ERROR_LOG("unload model failed, errorCode is %d", ret);
}
if (stream_ != nullptr) {
ret = aclrtDestroyStream(stream_);
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclrtDestroyStream failed, errorCode is %d", ret);
}
stream_ = nullptr;
}
if (context_ != nullptr) {
ret = aclrtDestroyContext(context_);
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclrtDestroyContext failed, errorCode is %d", ret);
}
context_ = nullptr;
}
ret = aclrtResetDevice(deviceId_);
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclrtResetDevice failed, errorCode is %d", ret);
}
ret = aclFinalize();
if (ret != ACL_SUCCESS) {
ERROR_LOG("aclFinalize failed, errorCode is %d", ret);
}
}
3、调用ResnetCls进行全pipeline的推理得到推理结果

int main()
{
const char* modelPath = "../model/resnet50_new.om";
const string imagePath = "../data";
int32_t device = 0;
int32_t modelWidth = 224;
int32_t modelHeight = 224;
// all images in dir
DIR *dir = opendir(imagePath.c_str());
if (dir == nullptr)
{
ERROR_LOG("file folder does no exist, please create folder %s", imagePath.c_str());
return FAILED;
}
vector<string> allPath;
struct dirent *entry;
while ((entry = readdir(dir)) != nullptr)
{
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0
|| strcmp(entry->d_name, ".keep") == 0)
{
continue;
}else{
string name = entry->d_name;
string imgDir = imagePath + "/" + name;
allPath.push_back(imgDir);
}
}
closedir(dir);
if (allPath.size() == 0){
ERROR_LOG("the directory is empty, please download image to %s", imagePath.c_str());
return FAILED;
}
string fileName;
ResnetCls Resnet(device, modelPath, modelWidth, modelHeight);
Result ret = Resnet.InitResource();
if (ret != SUCCESS) {
ERROR_LOG("InitResource failed");
return FAILED;
}
for (size_t i = 0; i < allPath.size(); i++)
{
fileName = allPath.at(i).c_str();
ret = Resnet.ProcessInput(fileName);
if (ret != SUCCESS) {
ERROR_LOG("ProcessInput failed");
return FAILED;
}
ret = Resnet.Inference();
if (ret != SUCCESS) {
ERROR_LOG("Inference failed");
return FAILED;
}
ret = Resnet.GetResult();
if (ret != SUCCESS) {
ERROR_LOG("GetResult failed");
return FAILED;
}
}
return SUCCESS;
}
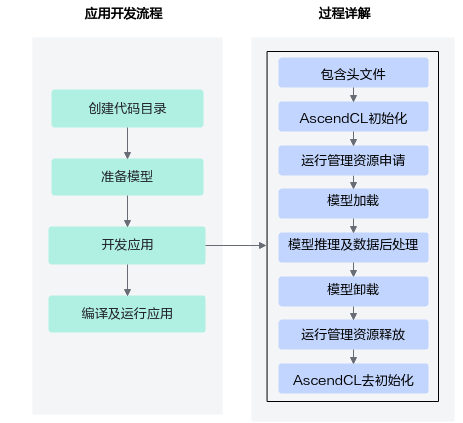
3.3 开发总结
整个开发流程可以总结为以下八个函数:因为用到了NPU资源,总体跟之前如ncnn后端推理的区别主要在于需要向NPU申请资源和分配内存,简单来说就是把输入copy到NPU上进行推理后再返回CPU做后处理操作。
-
定义一个资源初始化的函数,用于AscendCL初始化、运行管理资源申请(指定计算设备)
-
定义一个模型加载的函数,加载模型,用于后续推理使用
-
定义一个读图片数据的函数,将测试图片数据读入内存,并传输到Device侧,用于后续推理使用
-
定义一个推理的函数,用于执行推理
-
定义一个推理结果数据处理的后处理函数
-
定义一个模型卸载的函数,卸载已加载的模型
-
定义一个函数,用于释放内存、销毁推理相关的数据类型,防止内存泄露
-
定义一个资源去初始化的函数,用于AscendCL去初始化、运行管理资源释放(释放计算设备)
Ascend官网的流程图也很清晰:
第四章 基于OrangePi AIpro的刷掌识别系统
2023年5月,据微信公开课公众号称,微信刷掌支付正式发布,用户可以在刷脸设备上进行刷掌操作。
2023年5月22日消息,微信刷掌支付功能正式发布,用户可以在刷脸设备上进行刷掌操作。需要先在设备绑定个人微信账号,录入手掌纹样。消费时,将手掌对准支付设备的扫描区,确认后即可完成支付。
2023年9月5日消息,微信支付宣布,全国零售行业首发上线了微信刷掌支付,现已正式登陆广东711便利店1500+门店。
本博客初步实现“刷掌识别+Ascend”的demo案例,实际上刷掌识别是通过掌纹/掌脉/掌纹掌脉融合等特征来进行身份认证的,再进一步说就是图像分类问题,因此基于OrangePi AIpro中的Ascend AI芯片是完全可以实现这个任务的。
4.1 模型训练和模型导出转换
在Pytorch框架上搭建掌静脉识别模型训练框架,训练完成后得到预训练模型palm.onnx模型,模型输入为[1,1,224,224]的灰度图,本文主要聚焦于端侧的部署,因此不对模型训练作过多的阐述。
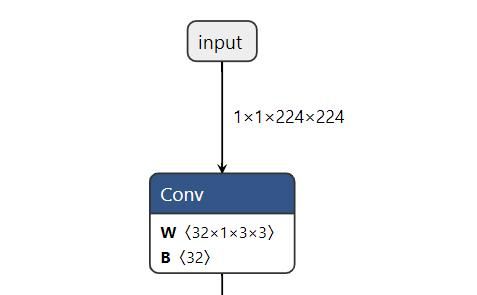
得到预训练模型palm.onnx文件,进入模型文件所在位置。通过onnx可视化可以看到模型的输入为1x1x224x224,且输入input_name即为input。
执行如下命令生成离线模型:
atc --model=palm.onnx --framework=5 --output=palm --input_shape="input:1,1,224,224" --soc_version=Ascend310B4
整体的代码框架如下:
palm_recognition
├── cmake-build-debug // 本地编译文件夹
├── cmake-build-debug-ascend // 远程编译文件夹
└── palm_recognition // 可执行文件
└── data // 多个不同人的掌静脉图片
└── 0.bmp
└── 1.bmp
└── 3.bmp
└── model // .om模型文件
└── palm.om
└── src // 认证代码,PalmAuthen类的实现
└── recognition.h
└── recognition.cpp
└── CMakeLists.txt // 链接库等
└── main.cpp // 程序入口
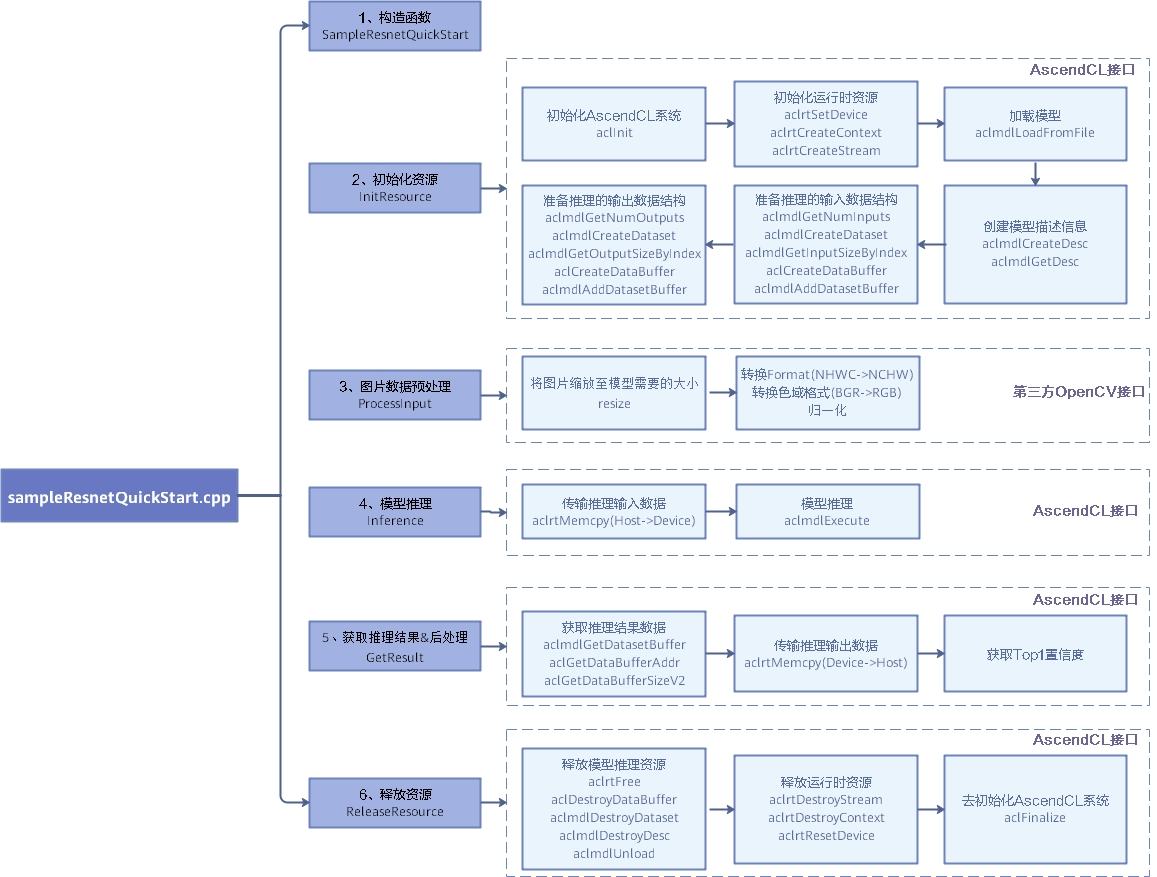
主要参照官方sample(sampleResnetQuickStart)的推理pipeline来进行整个框架的设计,对代码进一步进行封装,主要修改适配掌静脉识别任务:
-
针对灰度图进行标准化,根据模型训练的mean和norm对单通道图片进行标准化。
// data standardization
const float mean_value[1] = {0.5f * 255.f};
const float norm_value[1] = {1.f / 0.1f / 255.f};
// 标准化并拉平
for (int h = 0; h < resizeHeight; ++h)
{
for (int w = 0; w < resizeWeight; ++w)
{
int dstIdx = h * resizeWeight + w;
imageBytes[dstIdx] = static_cast<float>((resizedImage.at<cv::Vec3b>(h, w)[0] -
1.0f*mean_value[0]) * 1.0f*norm_value[0]);
}
}
-
修改后处理函数,官方sample是对输出的1*1000向量排序并进行softmax得到最后每个类别的概率值,如下
// 放入map并按照最大到小排序
map<float, unsigned int, greater<float> > resultMap;
for (unsigned int j = 0; j < len / sizeof(float); ++j) {
resultMap[*outData] = j;
outData++;
}
// 做softmax将概率归一化到[0,1]
double totalValue=0.0;
for (auto it = resultMap.begin(); it != resultMap.end(); ++it) {
totalValue += exp(it->first);
}
// 拿到概率最大的类别
float confidence = resultMap.begin()->first;
unsigned int index = resultMap.begin()->second;
string line = format("label:%d conf:%lf class:%s", index,
exp(confidence) / totalValue, label[index].c_str());
而我只需要拿到原始的输出1*512向量并做归一化。
// 放入result
result.clear();
for (unsigned int j = 0; j < len / sizeof(float); ++j) {
result.push_back(*outData);
outData++;
}
// 做归一化
normalize_feature(result, result, len / sizeof(float));
-
在main.cpp中对两张图片进行余弦相似度计算
string fileName = "../data/0_0.bmp";
auto start = chrono::high_resolution_clock::now();
net.ProcessInput(fileName);
net.Inference();
net.GetResult();
auto end = chrono::high_resolution_clock::now();
chrono::duration<double> inference_time_use = end - start;
INFO_LOG("Feature extract time: %f ms", inference_time_use.count()* 1000);
vector<float> result1 = net.result;
fileName = "../data/40_1.bmp";
start = chrono::high_resolution_clock::now();
net.ProcessInput(fileName);
net.Inference();
net.GetResult();
end = chrono::high_resolution_clock::now();
inference_time_use = end - start;
INFO_LOG("Feature extract time: %f ms", inference_time_use.count()* 1000);
vector<float> result2 = net.result;
// 输出余弦相似度距离[0,1],1为最相似
float sim=inner_product(result1, result2, 512);
INFO_LOG("similarity: %f", sim);
以下为同个人的手掌的相似度,两个不同人的手掌的相似度,根据设置sim的阈值就可以对每个人进行身份认证。


推理pipeline遵循以下逻辑。
第五章 OrangePi AIpro使用总结和评价
5.1 总结
本文主要做了以下几点工作:
-
拿到OrangePi AIpro之前在虚拟机Ubuntu 2022.04上搭建CANN开发环境,为后续板端推理配合做模型转换工作,得到适配昇腾AI处理器(Ascend310B4)的离线模型xx.om。
-
开箱并测试 OrangePi AIpro开发板的功能,同时体验了0-1从烧录到运行系统跑通样例代码的过程并做记录。
-
基于samples/inference/modelInference/sampleResnetQuickStart 在CLion上搭建工程并远程编译运行图像分类功能。
-
基于3的工作将图像分类应用到刷掌识别领域,设计轻量化模型并成功转换模型部署到了OrangePi AIpro上,基本实现了最核心的识别功能,推理性能相比之前CPU推理的后端框架快了将近10倍。
5.2 使用体验
-
OrangePi AIpro搭载了昇腾Ascend310B4处理器,可提供8TOPS INT8 的计算能力,将AI推理任务Memcpy到NPU上推理后再返回到Host,大大加快了推理速度。性能的强大使得跟多有意思的AI应用可以部署,如视频理解这种任务。
-
Ascend的官方提供的资料,包括ATC工具使用、ACL开发、ACL接口文档等等都非常齐全,并且在开源仓库提供了很多示例代码,非常有助于初学者上手并开发自己的第一个AI应用,让开发者可以便捷高效的编写在特定硬件设备上运行的AI应用程序。
-
OrangePi AIpro板子本身提供了非常丰富的外设和接口,可以在此基础上结合项目需求做到软硬件配合。

昇腾万里,让智能无所不及
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)